딥러닝 모델링을 위해서는 데이터를 정규화 해주는 것이 좋습니다. 정규화를 안해도 학습이 되는 경우가 있긴합니다. 그러나 딥러닝은 gradient descent 방식을 통해 학습을 합니다. 정규화를 진행시켜주어야 이러한 학습이 잘 작동을 하고, 대부분의 경우 아주 쉬운 문제일지라도 정규화를 해주지 않으면 학습이 안 될 수도 있습니다.
주식 데이터도 딥러닝을 통해 학습하기전에 정규화를 해주는 것이 좋겠죠. 그렇다면 어떤 방식으로 정규화를 해야할까요? 라는 문제는 다음에 포스팅하겠습니다. 어떻게 정규화를 할지를 고민하다가, EDA를 하게 되었지만 글 순서는 반대가 되었군요.
저는 주식의 데이터를 0~1로 정규화 하고자 합니다. 그리고 Min-max 방식으로 진행할 것인데, 그렇다면 어떤 값을 min과 max값으로 해야 할까요. 또 저는 주식을 딥러닝으로 모델링 할때 데이터를 나누는 방식인 Data Rolling Segmentation을 사용할 것입니다. 예를들어 10년 치 데이터를 학습할 때, 1년을 학습하고, 다음 1년을 학습하고... 이런식으로 데이터를 일부분만 사용해서 계속 훈련 시키는 방식입니다.
또 예를 들어 1년을 학습한다고 합시다. 머신러닝, 딥러닝은 과적합을 막기 위해서 꼭 Train / Test Split을 해야 합니다. 9개월을 Train set, 3개월을 Test set이라고 합시다. 정규화 과정에서 Test Set까지 포함해서 단순히 Min_max 정규화를 해버리면 문제가 있을 수 있습니다. Test set에서의 고가 또는 저가가 Min, Max값으로 지정이 될 수 있고, 그렇다면 Train set을 정규화 할때에 영향을 줄 수 있습니다. 바꿔 말하면 훈련에 사용 된 Train set과 Test set이 영향을 주고 받는 것이고, 이를 test set이 오염됐다고 표현하기도 합니다.
과적합을 막기 위해서, 마치 처음보는 데이터인 것처럼 Test set으로 결과를 평가해야 하는데, 이미 Test set의 일부 특성(분포)를 학습을 하게 됩니다. 즉 과적합을 방지할 수가 없습니다.
단순히 Train set의 값의 고가, 저가를 min, max값으로 저장하는 것은 간단하긴 하지만 실제 활용하기에는 문제가 있을 수 있습니다. 위의 예시처럼 9개월의 Train set의 값으로 정규화를 진행했다고 해봅시다. 이 정규화 과정에서 사용한 정규화 함수를 Test set에 그대로 적용할 수가 있겠죠. 그런데 만약 3개월 동안 주식이 많이 상승하거나 많이 하락했다면 어떻게 될까요. 9개월 동안의 고가는 3만원 이었는데, 3개월동안 1~2만원이 오른 것입니다. 실제로 이런 경우는 있을 수 있습니다.
이전글에도 말씀드렸겠지만 딥러닝이 최근에 잘 학습이 되긴 하지만 여전히 train set에서 보지 못한 데이터의 분포는 예측하기 쉽지 않습니다. 0~1 범위 에서의 데이터를 학습했는데, test 기간 동안 1이 넘어가는 데이터들만 존재하면... 테스트의 결과가 끔찍할 것 입니다.
그래서 제가 생각한 방식은, 제가 가지고 있는 데이터 내에서, train set 기간의 데이터에 비해서 test set 기간의 데이터는 얼마나 차이가 있는가? 입니다. 그 차이가 어떤지 알게 된다면, train set 기간의 데이터를 이용해서 적절한 min, max 값을 유추해낼 수 있지 않을까 싶어서 입니다. 그래서 아래의 eda를 진행하게 되었습니다.
사용한 데이터는 2010년 ~ 2018년 말 까지의 일봉 데이터 입니다. 총 117개의 주식 종목을 사용했습니다. 전체 주식 종목 중 117개를 선택한 이유는... 제가 예전에 포스팅한 [https://dataplay.tistory.com/7]를 참고해주세요. 취향에 따라서 본인이 가지고 있는 주식 종목을 사용하시면 되겠습니다요.
제가 알아내고자 한 내용들은 다음과 같습니다.
(데이터는 '종가' 이용. M = Train set의 기간, N = Test set의 기간)
1. 0 시점의 가격과 N 기간 동안의 고가 비교
2. 0 시점의 가격과 N 기간 동안의 저가 비교
3. M 기간의 고가와 N 시점 기간 고가 비교
4. M 기간의 저가와 N 시점 기간 저가 비교
1,2 번은 오늘 가격과 비교해서 N일 동안 얼마나 높이 올라가고, 얼마나 낮게 내려갈 수 있는가를 볼 수 있습니다.
3,4번은 이전 M기간 동안의 고가와 저가에 비해서 다음 N기간 동안 고가와 저가에 변화가 얼마나 있는가를 보는 것입니다. 3,4 번이 min_max 정규화를 할때 더 유용한 데이터를 줄 것으로 보입니다.
.
import os
import numpy as np
import pandas as pd
import plotly.graph_objects as go
path_dir = './data'
file_list = os.listdir(path_dir)
cl_N_max_val = []
cl_N_min_val = []
M_N_max_val = []
M_N_min_val = []
M = 240
N = 60
for item in file_list :
if item.find("from") is not -1 :
data = np.loadtxt(path_dir + '/' + item, delimiter = ',')
data = pd.DataFrame(data)
data.columns = ['Open', 'High', "Low", "Close", "Volumn", "Adj"]
data = data[["Close", "Open", "High", "Low", "Volumn"]]
rol_N_max = np.array(data["Close"].rolling(window=N, min_periods=1).max())
rol_N_min = np.array(data["Close"].rolling(window=N, min_periods=1).min())
rol_M_max = np.array(data["Close"].rolling(window=M, min_periods=1).max())
rol_M_min = np.array(data["Close"].rolling(window=M, min_periods=1).min())
close = np.array(data["Close"])
cl_N_max_val.append(np.max((rol_N_max[N:] - close[:-N]) / close[:-N]))
cl_N_min_val.append(np.min((rol_N_min[N:] - close[:-N]) / close[:-N]))
M_N_max_val.append(np.max((rol_N_max[M+N:] - rol_M_max[M:-N])/ rol_M_max[M:-N]))
M_N_min_val.append(np.min((rol_N_min[M+N:] - rol_M_min[M:-N])/ rol_M_min[M:-N]))위와 같은 코드로 값들을 계산했습니다.
1. cl_N_max_val
2. cl_N_min_val
3. M_N_max_val
4. M_N_min_val
로 각각 계산을 한 것 입니다.
조금 더 자세히 설명하자면
1번은 0시점의 종가와 0시점 이후 N 기간 동안의 고가를 비교한 것 입니다. 0시점의 종가와 N 기간 동안의 고가의 차이의 비율을 구하고, 그 비율 중의 최대치 입니다. 이 값을 통해서 알 수 있는건, 이 최대치 이상의 비율로 주가가 상승 한 적은 없었다는 의미 입니다. 2번 값도 비슷하지만, 최저치를 기준으로 계산한 것 입니다.

각각의 값들에 각각 최고치, 최저치를 계산해보았습니다. N=60 으로 설정해둔건 60거래일인데, 대략 3달이 좀 안되는 기간입니다. 보시면 3달 동안 제에에에에일 많이올라야 45%. 제에에에에일 많이 떨어지면 1/3 정도까지 떨어지는 군요. 그리고 보시면 1,2 번 계산값에 비해 3,4번 계산값의 최대치와 최저치 범위가 더 작은걸 보실 수 있는데, 코드에서 범위를 참고해주시면 좋겠습니다.
그리고 3달 동안 많이 올라야 45%? 물론 이것도 정말 많이 오른 것이긴 한데, 더 높이 오르지 않을까? 라고 생각할 수 있습니다. 데이터의 범위 자체가 10년치인 것도 있지만, 117개로 줄였을때 2010년 첫 거래일의 종가가 4천원 이하인 종목은 자르는 등의 처리를 해준 것도 이유가 됩니다.
또 재밌는 점은, 금일의 종가에 비해서, 3달 동안의 고가가 더 낮은적은 없고, 3달 동안의 저가가 더 높은 적도 없습니다. 이말은 왠만한 주식은 잘못사도 3달동안 한번은 손절할 타이밍이 있지 않을까...
117개의 데이터를 다 살펴보는 건 눈이 아파서 시각화를 해봤습니다.
.
fig = go.Figure(data=[go.Histogram(x=cl_N_max_val,
histnorm='probability',
xbins=dict(
start=0.0,
end=1.5,
size=0.25
),)])
fig.update_layout(
title_text='cl_N_max_val', # title of plot
xaxis_title_text='Value', # xaxis label
yaxis_title_text='Prob' # yaxis label
)
fig.show()위의 코드를 조금씩 변형해서 아래의 그래프들을 그렸습니다. 그래서 코드는 생략하도록 하겠습니다.


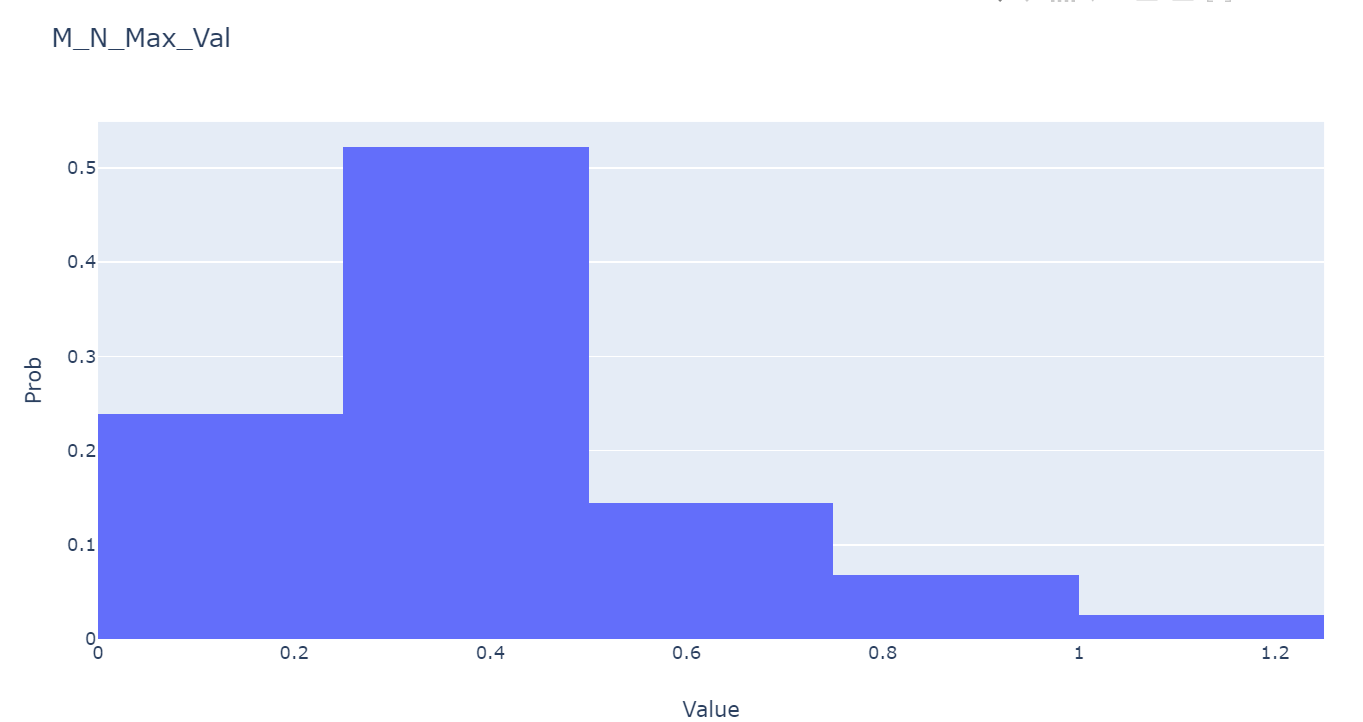

아래 두개의 plot을 살펴보겠습니다.
M_N_Max_Val은 다시 풀어서 말하자면 각 종목별로 1년동안의 max값과 그 다음 3달간의 max값의 차이를 비교합니다. 그리고 그 차이값이 가장 큰 값들만 모아놓은 value들 입니다. 약 절반의 종목들이 3달간 가장 많이 오르는 값이 0.25~0.5 입니다. 이건 1.25~1.5배 라는 얘기고, 3달동안 가장 많이 오르는 값이 1.25배 이하인 종목이 25% 정도 되네요.
M_N_Min_Val은 위와 반대되는 값으로, Min값의 차이를 비교하여 그 차이값이 가장 작은값, 그러니까 가장 많이 떨어진 value들을 모아놓은 것입니다. -0.7 ~ -0.5 사이가 엄청 낮은것으로 볼 수 있고 각 bin에 하나의 종목이 있습니다. 3달동안 1/3~ 1/2 토막이 난 종목이 있다는 것입니다. 반면 -0.1~0 사이에 있는 종목은 Min 값이 별로 안낮아지는 것입니다.
위 두개의 값들을 굳이 살펴본 이유를 다시 정리해보겠습니다. 1년간의 주가로 훈련을 시킨 모델로 3달 간의 주가를 예측해야 합니다. 1년간의 주가로 min, max값을 설정을 하면 훈련을 잘 되겠지만 test set에서 잘 작동하지 않을 확률이 큽니다. 데이터 범위가 문제인데, test 값을 통해서 min, max값을 훈련시키면, test set에서 성능이 나오겠지만 실제 환경에서 적용이 안되는 과적합이 발생합니다.
그래서 제가 생각한 방법은 train set의 데이터 만을 통해서 적절한 min, max값을 추론해고자 합니다. 추론한 min, max값이 모든 test set의 데이터도 0~1 사이로 정규화 시켜야 합니다. 위의 plot들로 보았을때 10% 정도의 극단치를 제거한다면 max 값은 1.75배, min 값은 0.5배 정도를 하면 적당하지 않을까 싶습니다. 1년동안의 max값이 2만원이고, min 값이 1만원 이라면 max를 35,000원, min 값은 5,000원으로 설정할 수 있겠네요.
.
M_N_max_mean_val.append(np.mean((rol_N_max[M+N:] - rol_M_max[M:-N])/ rol_M_max[M:-N]))
M_N_min_mean_val.append(np.mean((rol_N_min[M+N:] - rol_M_min[M:-N])/ rol_M_min[M:-N]))마지막으로 궁금해서 위와 같은 코드를 맨 위의 코드에 추가해서 변수를 계산해보았습니다.
첫번째 변수는 1년 동안의 max 값과 다음 3개월 동안의 max 값의 차이를 계산해서 그 차이를 종목별로 평균을 내보았습니다.
두번째 변수는 1년 동안의 min 값과 다음 3개월 동안의 min 값의 차이를 계산해서 그 차이를 종목별로 평균을 냈습니다.

그리고 위 두변수를 평균을 내서 출력했습니다. 각 종목별로 전체 기간동안 계산해봤을때 지난 1년에 비해서 다음 3개월간의 max값과 min값을 비교한 것입니다. max값은 평균적으로 내려가고... min 값은 평균적으로 올라갑니다. 아무리 코스피가 박스피라지만, 왜 max값이 평균적으로 내려갈까요?
제 생각은 다음과 같습니다. 주식은 상당히 변동이 큰 자산이죠. 그래서 내재가치와 관계없이 올라가고 내려가고를 반복합니다. 그래서 올라갈 확률도 있고 내려갈 확률도 있는데 평소보다 많이 올라갈 사건이 3개월 보다는 1년 동안 더 많을 것 입니다. 따라서 1년 동안의 max값이 클 확률이 높은 것입니다. 그래서 실제로 N을 3개월로 설정하지 않고, 1년으로 설정한다면 저 값이 양수를 보입니다.
비슷한 의미로 평소보다 많이 떨어질 사건이 1년 동안에 더 많이 발생하겠죠, 따라서 평균적으로 1년 동안의 min 값보다 그 다음 3개월의 min값이 더 높을 수 있습니다.

그래서 결론적으로는 딥러닝에서 사용할 데이터를 정규화 할때는 위의 eda를 바탕으로 함수를 계산해보도록 하겠습니다.
'주식 데이터 모델링' 카테고리의 다른 글
| 딥러닝으로 캔들스틱 차트 이용해서 주식 예측 - 예제코드 (10) | 2019.12.01 |
|---|---|
| 딥러닝으로 캔들스틱 차트 이용해서 주식 예측 - 논문요약 (1) | 2019.11.27 |
| 시계열 데이터 분석에 딥러닝을 사용할 이유 3가지 (1) | 2019.10.26 |
| LightGBM으로 주식 모델링 해보기 [머신러닝] - Classification, 머신러닝으로 모델링이 가능한가? (0) | 2019.10.25 |
| LightGBM으로 주식 모델링 해보기 [머신러닝] - Regression (0) | 2019.10.24 |


