0. 소개
오늘은 Tensorflow 등의 프레임워크에서 CNN의 특이한 파라메터를 몇가지 알아보도록 하겠습니다.
Transposed Convolution은 이름 그대로 반대로 작동하는 Convolution 입니다. 보통 Convolution은 padding이 없을시 feature를 뽑아내면서 이미지의 크기는 작아지게 됩니다. 하지만 Transposed Conv는 거꾸로 이미지의 크기를 더 커지게 만듭니다.
Dilated Convolution은 Convoltion filter를 적용할 때, n칸 간격 만큼 건너 뛰며 filter를 적용하는 것 입니다.
Causal Convolution은 time step t의 output을 내기 위해서 time step t까지의 input만 고려하는 방식입니다. 시간, 순서를 고려할때 유용하게 사용할 수 있죠.
1. Transposed Convolution
Transposed Conv가 작동하는 방식을 사진으로 보여드리겠습니다. Transposed convolution을 소개한 논문 링크 입니다.
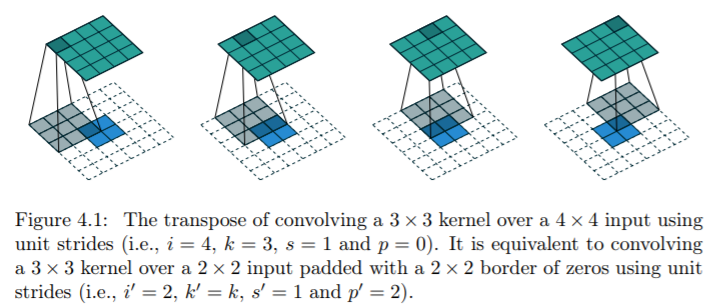
위의 연산을 구현해놓은 Tensorflow의 API는 conv2d_transpose 등 입니다. Stride, Padding, filter size, 그리고 뒤에서 설명할 dilations 등의 파라메터를 조정이 가능합니다. 파라메터의 조정으로써 원하는 크기의 이미지를 만들어낼 수 있는거죠.
위의 사진은 2x2 이미지에 Transposed Conv를 적용시켜서 4x4 이미지를 만든 것 입니다. 3x3 filter, 그리고 padding을 이용해서 만든 것 입니다. Upsampling을 수행하는 Layer를 만든 것이죠.
이러한 Transposed Convolution이 사용 되는 모델의 종류는 다양합니다. 예를 들어 CNN을 사용한 Encoder-Decoder 구조의 Autoencoder 입니다. Encoder에서 Pooling 등을 통해 이미지를 축소시키면서 데이터를 압축했다면, 그 데이터를 다시 원래의 이미지로 복원하기 위해 이미지를 크게 만들어야 합니다. 이럴때 사용 할 수 있는 방법 중 하나가 되겠네요.
그리고 아예 모델의 목적이 이미지의 해상도를 높이는 것 일수도 있습니다. Super resolution이라고도 불리는 기법인데, 이 기법을 딥러닝으로 구현하게 되면 input 이미지보다 output 이미지의 크기를 커지게 만듦으로써 가능하겠죠. 이럴때 사용하는 방식이 Transposed Convolution 입니다.
이미지 크기를 크게 하는 방법이 Transposed Conv 만 있는 것은 아닙니다. 보간 이라는 방법이 있는데, 데이터를 크게 만들때 필요한 정보들을 수학적인 알고리즘을 바탕으로 채우는 것 입니다. 보간 방식에 비해 얻을 수 있는 장점은, 딥러닝 방식으로 파라메터들을 학습하는 것 입니다. 학습이 잘 된다면 기존 보간 방식에 비해 정확한 정보를 얻을 수 있습니다.
Deconvolution도 보기에는 Transposed Conv와 같은 것이 아니냐? 라고 할 수 있지만, Deconvolution은 Convolution의 역산으로 Convolution layer를 거치기 전의 input을 추정하는 과정 이라서, 엄밀히 말하면 계산 자체가 다릅니다. 그러나 실제로 Deconvolution을 사용하는 경우를 본적은 없어서, 같은 의미로 말하는 분들도 있을 거라 생각됩니다.
2. Dilated Convolution
Dilated Convolution을 설명하기 전에 Receptive Field의 개념을 알아야 합니다.
Receptive Field는 filter가 한번에 보는 영역으로 생각하면 됩니다. 일반적인 3x3 filter size는 receptive field가 3x3 이미지 입니다. 그리고 이러한 layer를 두개, 세개 쌓으면 receptive filed가 5x5, 7x7 이런식으로 늘어나게 됩니다. Receptive field가 늘어난 다는 것은 output을 계산할때 사용하는 정보의 양이 많다는 것 입니다.
정보의 양이 늘어나면, 성능이 좋아질 확률도 높아지지만, 학습해야 할 양이 많아서 연산량이 증가하게 되는 단점도 있습니다. 이 Receptive field를 높이기 위해서 filter의 크기를 키우거나, layer를 늘릴 수 있습니다. 또는 pooling 등을 사용하는 것도 receptive field를 높일 수 있습니다. Poling의 경우 연산량 까지 감소할 수 있지만 정보의 손실을 가져올 수도 있죠.
Dilated Convolution은 Receptive field를 크게 만들어서 커버하는 영역을 크게 만들면서, 연산량의 증가는 가져오지 않는 효과적인 방법입니다.
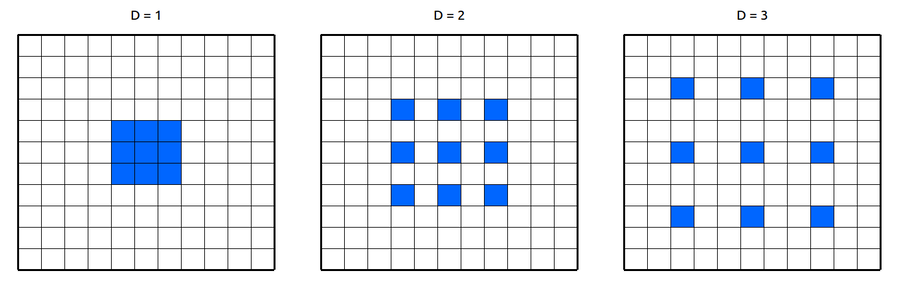
위의 사진이 Dilation Factor를 1, 2, 3으로 각각 설정하고, Filter size를 3x3으로 설정했을 때의 사진 입니다. 보시다시피 Dilation의 크기가 늘어날 수록, filter가 추출해내는 input의 간격이 멀어지는 것을 볼 수 있습니다. D=1 일때는 receptive field가 3x3 이지만, D=2 일때는 receptive filed가 5x5 이죠. Receptive Field는 늘어났는데, 연산량은 증가는 없습니다.
저렇게 filter가 sparse하게 feature를 추출함으로써 일어나는 손실도 있을 수 있겠으나, Receptive Field의 크기가 중요한 경우에는 아주 잘 작동한다고 알려져 있습니다. 예를 들어 Audio의 경우에 1초당 보통 16000~22500개의 sample이 존재하는데, Dilated Convolution 방법을 통해 몇개의 layer를 통해서 많은 sample을 커버 할 수 있죠.
3. Causal Convolution
Causal Convolution은 위 두개의 개념들보다는 사용하는 경우가 좀 적습니다. 그래서 그런지 자료도 많이 없습니다. Causal Convolution에 대해 찾아보시면 Wavenet과 관련 된 자료가 많습니다.

Wavenet은 음성을 고품질로 합성해내기 위한 모델로써, 음성은 시계열 데이터 입니다. 예를들어 10000번째 샘플을 생성해내기 위해서 10001번째 데이터를 사용하게 되면 안됩니다. 이런 경우 시계열 데이터를 모델링 하기 위해 RNN 계열을 사용하는 경우가 많은데, RNN 계열은 학습이나 실제 Test 시간이 오래걸리는 등의 단점이 존재합니다.
위의 단점을 보완하기 위해서 CNN을 시계열 모델링에 사용하게 됩니다. 위의 사진 처럼 순서(시간)을 고려한 구조를 만들어서 말이죠. 특히 Wavenet은 Causal 개념과 Dilated 개념을 합쳐서

이러한 모델 구조를 만듭니다. 엄청난 크기의 Receptive field를 가지는 model 구조를 만들어낸 것이죠.
Causal Convolution은 딥러닝 프레임워크에 따로 API를 두지 않는 경우가 종종 있습니다. 이 경우에 padding과 데이터 slicing을 통해 구현하실 수 있습니다.
위의 Convolution들 관련해서는 필요하다면 따로 예제 코드를 올려보도록 하겠습니다.
'딥러닝' 카테고리의 다른 글
| 11. Activation Function (활성화 함수) (0) | 2019.11.18 |
|---|---|
| 10. Transfer Learning (0) | 2019.11.16 |
| 8. CNN - 1x1, 3x3, 5x5, 예제 코드 (0) | 2019.11.13 |
| 7. CNN - VGG, Resnet 예제 코드 (2) | 2019.11.13 |
| 6. CNN - Convolutional Neural Network 예제 코드 (0) | 2019.11.12 |



