이전 GAN 소개글에 이어서 GAN의 구현에 대한 글을 작성해보겠습니다.
전체 코드는 늘 그렇듯이 코랩에 작성해두었습니다. (https://colab.research.google.com/drive/1v7OYMjLF1zkYUzcuCSUdpzUmIm_dCPPz#scrollTo=9R6X81WJsyqmhttps://colab.research.google.com/drive/1v7OYMjLF1zkYUzcuCSUdpzUmIm_dCPPz)
참고한 코드는 Tensorflow2의 공식 튜토리얼 입니다. (https://www.tensorflow.org/tutorials/generative/dcgan)
1. 데이터
GAN은 훈련시키기가 무척이나 어려운 구조 입니다. 그래서 간단한 MNIST 데이터를 이용했습니다. 사실 이 데이터를 생성해내는 것도 쉽지는 않습니다. 그리고 GAN은 실험적으로 결과가 좋다는 이유로 사용하는 몇가지 방식이 있습니다. ReLU 대신에 leaky ReLU를 쓴다던가, G모델과 D모델의 마지막 activation function으로 sigmoid 대신에 tanh 함수를 선호한다던가 그렇습니다.
Tanh 함수는 -1과 1사이의 값을 출력합니다. 따라서 MNIST 데이터를 ~1과 1 사이의 값으로 정규화를 진행했습니다.
2. Vanlia GAN 구조
이번 예제코드에서는 3가지 GAN 구조를 작성했습니다. 순서대로 Vanlia GAN, Deep Convolution GAN, Conditional DCGAN 입니다. DCGAN와 Conditioncal DCGAN은 Vanlia GAN에 비해서 layer 수가 늘어나거나, 추가정보가 더 들어간 구조입니다. 따라서 GAN의 loss나 훈련 방식은 거의 동일합니다.

G모델은 100 차원의 random noise로부터 MNIST 데이터의 이미지를 생성하는 모델입니다. Layer는 아주 간단하게 Dense layer 2개로 구성이 되어 있습니다. LeakyReLU와 tanh를 각각의 활성화 함수로 사용하는 이유는 1번에서 말씀드렸다시피 실험적으로 좋은 결과를 주었기 때문입니다.

D모델은 28*28 이미지가 input으로 들어오면 이게 실제 sample인지 아니면 G모델에서 만들어진 가짜 sample인지를 판별하게 됩니다.

아직 훈련을 시키지 않은 G모델과 D모델을 사용해보면 위와 같은 출력을 보입니다.
3. GAN 훈련 구현

각각 D모델의 loss와 G모델의 loss 입니다. D 모델은 진짜와 가짜를 잘 판별해야하고, G 모델은 D모델을 속여야 하는 겁니다.
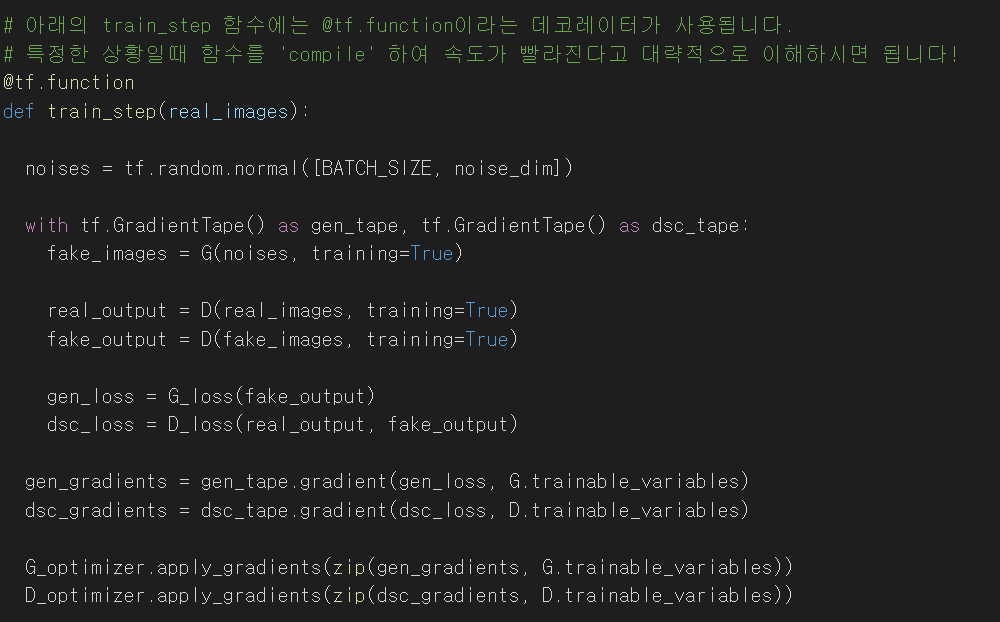
GAN은 훈련을 할때 위와 같이 훈련 코드를 평소보다는 조금 더 자세히 작성해야 합니다. 평소에는 model의 구조를 만들고, model.fit 이런 함수를 통해 훈련을 진행합니다. 위 코드는 model.fit 함수에서 일어나는 일들을 GAN 훈련 방식에 맞게 다시 써줬다고 생각하시면 됩니다.
매 훈련 스텝마다 랜덤 노이즈를 통해서 샘플을 생성해야 합니다. 그래서 noise를 만들어주고, 이 noise를 G모델을 통과시켜 fake_image를 만들어줍니다. D모델은 진짜 샘플은 진짜로, 가짜 샘플은 가짜로 판별을 해줘야 합니다.
이렇게 G모델로 fake_imgae 생성 해준뒤, D모델에 진짜 샘플과 가짜 샘플을 판별하게 한뒤에 loss를 계산해줍니다. 이 loss를 통해 G모델과 D모델의 gradient를 계산해주고, optimizer(여기선 adam)를 통해서 파라메터를 업데이트 해줍니다.

그리고 위와 같은 train 함수를 이용해서 설정한 epoch에 맞게 모든 dataset을 사용해서 훈련을 진행합니다. 과연 결과는 어떨까요?

뭔가.... 애매합니다. 사실 label 정보가 주어지지 않고 단순한 noise라서 원하는 숫자를 만들수는 없습니다. 그래도 GAN이 잘 훈련이 되었다면 MNIST에서 나올법한 숫자가 나와야 합니다. 위와 같은 품질의 문제를 해결하기 위해서 DCGAN이 나왔습니다.
4. Deep Convolutional GAN


각각 G모델과 D모델의 구조입니다. 확실히 Vanlia GAN 보다 모델이 deep 해진 것을 알수 있고, Convolution layer가 주를 이룹니다. 이미지 분류등의 모델에서 큰 이미지를 점점 작게 만들면서 filter 수는 높이는 구조를 볼 수 있습니다. 위 G모델에서는 그와 반대로 noise에서 작은 이미지 + 높은 filter 수의 이미지를 먼저 생성하고, 점점 이미지를 크게 만들고 filter수를 줄이는 방식입니다. 이미지를 크게 만들때 Transposed Conv를 이용하고 있습니다.
그 외의 훈련코드는 그대로 사용합니다.

결과는 이렇습니다. Vanlia GAN에 비해서 배경에 noise가 없어지긴 했습니다만. 아직도 숫자를 제대로 알아보기는 쉽지 않습니다. 원래 GAN 훈련이 참 쉽지 않은 부분이라... 그렇습니다.
5. Conditional DCGAN
머신러닝, 딥러닝에서 추가적인 데이터는 대부분의 경우 훈련에 긍정적입니다. 특히 GAN 처럼 생성모델의 경우 추가적인 데이터를 통해서 생성모델이 '무엇을' 생성할지를 결정할 수도 있게 되어 특히 중요합니다. 다만 이 추가적인 데이터를 어떻게 모델에 주느냐도 정말 중요합니다.
이러한 추가적인 정보를 모델에 어떻게 input 하냐에 따라서 훈련을 방해할 수도 있고, 아니면 정보를 효과적으로 사용할 수 없는 경우도 있습니다.
MNIST 데이터에서 추가로 사용할 수 있는 정보로는 label 정보가 있습니다. 잘 훈련이 된다면 이 label을 이용해서 어느 숫자를 생성해낼 것인지도 결정할 수 있는 중요한 정보 입니다. 저는 label 정보를 one-hot encoding 형태로 바꾸어서 모델에 추가했습니다. 숫자 3인 경우에 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0] 형태로 만든 것입니다. 이 label 정보를 어떻게 DCGAN 모델에 넣을까요?
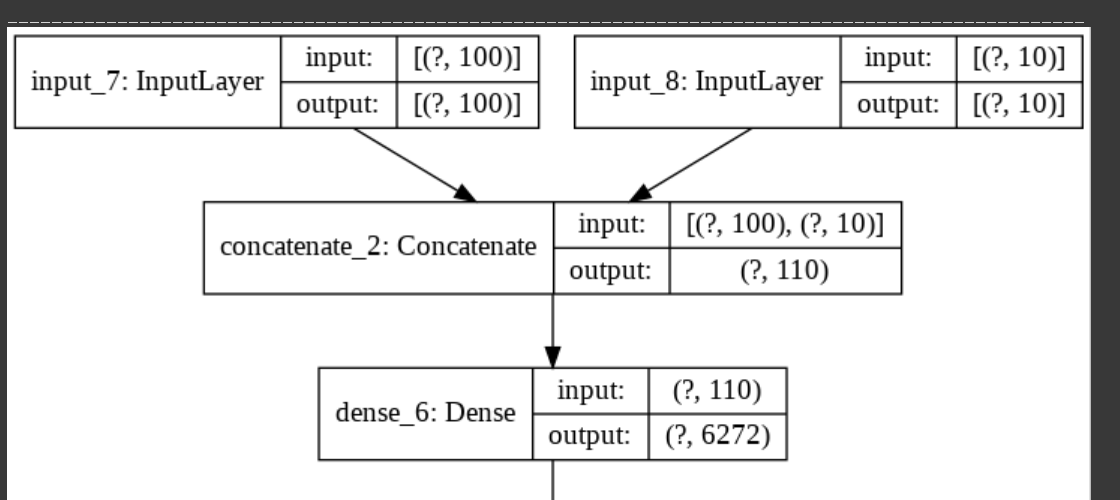
G모델의 경우에는 맨처음 noise와 one-hot encoding label을 바로 concatenate 해줬습니다. 이런식으로 정보를 넣어주면 G모델의 모든 layer에서 label 정보를 사용하게 됩니다.

D모델의 경우는 위와같이 넣어주었습니다. D모델의 기존 input은 28*28*1 사이즈의 이미지가 됩니다. 10차원의 label을 28*28*1 크기로 맞춰주기 위해 dense layer와 reshape를 이용했습니다.
Conditioning 방식은 딱히 정해져 있는 방식이 없습니다. 다만 아까 말씀드렸다시피 중요한 정보를 모델이 훈련에 충분히 이용할 수 있도록 해줘야 한다는 것과, 훈련을 방해하면 안된다는 것 입니다.
위와 같이 모델 구조를 바꾸어주었고, 추가적인 정보를 이용하기 위해서 훈련 함수를 약간 변경하였습니다. 이건 colab에서 함수로 확인해주시기 바랍니다. 이번 Conditional DCGAN에서는 loss를 추가로 확인하기 위해 loss를 epoch마다 저장해서 loss curve를 확인했습니다.
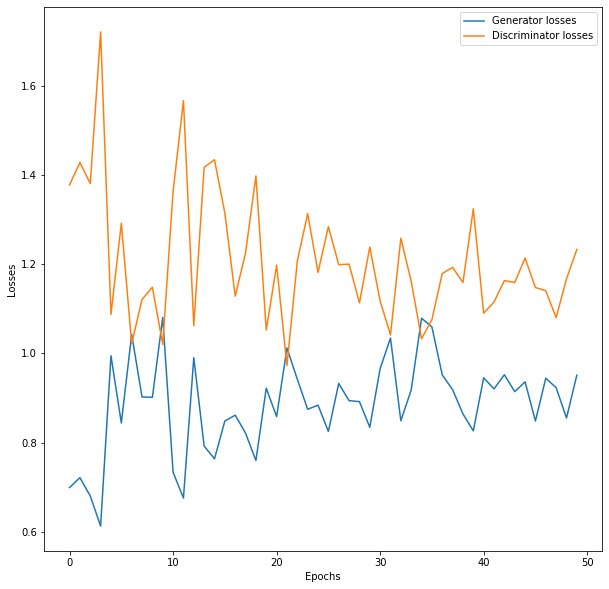
대부분의 딥러닝에서 loss는 말그대로 '손실'을 의미하기 때문에 0에 가까울 수록 좋습니다. 하지만 GAN은 조금 다릅니다. D모델이 하는 역할은 진짜와 가짜를 구별하는 것입니다. 그런데 만약 D모델의 loss가 0이 됐다면, 진짜와 가짜를 완벽히 구별 할 수 있다는 의미입니다.
G모델의 역할은 랜덤하게 생성한 이미지가 D모델이 진짜인지 가짜인지 구별을 하지 못하도록 하는 것 이죠. D모델의 loss가 0이라면 G모델은 진짜 같은 이미지를 생성하지 못한다는 의미 입니다. 그래서 이론적으로는 D모델의 loss가 1로 수렴하는 것이 이상적입니다. 특히 진짜와 가짜 구별을 완벽히 못해서 어떤 이미지가 들어오더라도 진짜일 확률 0.5, 가짜일 확률 0.5를 내뱉는 것이죠. 위의 loss를 보시면 D loss가 1과 가까운 것을 볼 수가 있습니다.

Conditional DCGAN의 장점은 아까 말한것처럼 추가적인 정보를 통해서 더 이미지를 잘 생성해낼수도 있고, 원하는 label에 맞게 이미지를 생성할 수도 있습니다. 위의 경우에는 각각 0~9 까지의 이미지를 생성한 것입니다. 그래도 이번 예제코드 중에서는 제일 괜찮네요. 0,1,3,4,5,9는 특히 누가봐도 그 숫자를 그린 것 같습니다.(아닌가...?)
이 이후에도 정말 많은 GAN이 등장했습니다. 이번 예제코드를 통해서 생성모델에 관심이 생기셨다면 많이 찾아보시는걸 정말 추천드립니다. 요즘에는 숫자 뿐만 아니라 건물, 사진, 인물등을 GAN으로 생성하기도 합니다. 물론 논문에서 보여주는 것만큼 결과가 잘 나오지는 않지만... 발전 가능성이 충분히 있습니다.
'딥러닝' 카테고리의 다른 글
| 16. GAN - 생성모델 (0) | 2019.12.03 |
|---|---|
| 15. AutoEncoder 예제코드 (0) | 2019.11.26 |
| 14. AutoEncoder (0) | 2019.11.23 |
| 13. RNN (순환 신경망) (0) | 2019.11.20 |
| 12. Learning Curve (학습 곡선) (2) | 2019.11.19 |



